In this document we will explain in detail how to configure the file sequence filter in the Input Filter.
1. Create a new channel
Create a new File Processor channel with a folder input and a printer output. If you have never used the File Processor, and connect for the first time, there will be no File Processor channels.
2. General information
We will explain the file sequence by using an example. Files are dumped into a folder which is monitored by the File Processor.
The requirement is that two files (a .docx and a .pdf) with a same number in the file name should be printed. The .pdf should be printed first and printing can only start when both files are in the folder.
Let's say the directory has these files:
report0001.docx
0002cover.pdf
0001cover.pdf
report0002.docx
They should be combined and printed in this order:
0001cover.pdf
report0001.docx
and
0002cover.pdf
report0002.docx
The idea is that we create two conditions in the [File Sequence] filter. A first condition to select the cover .pdf file and a second condition to select the report .docx. By defining the cover .pdf file first and the report .docx last, you automatically fulfill the requirement of the file order (.pdf will be printed first). The next step will be to select the files with the same number. This will be done by defining a [Group by value] for each condition.
3. Configuration
In the [Channel Options] go to the [Input Filter]:

Add a filter part by clicking the [+] sign and select the [File Sequence] filter option:
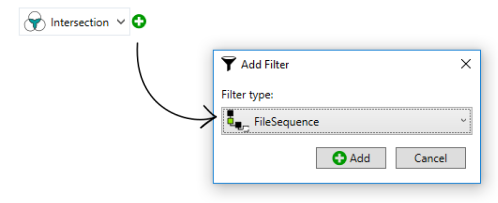
After adding the [File Sequence] filter your [Input Filter] should now look like this:
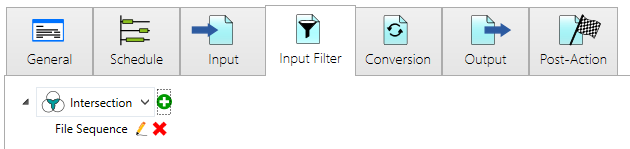
Now let us configure the [File Sequence] by clicking the pencil-icon to open the editor:
Create two conditions because we need to select two files (.pdf and .docx). You do this by clicking two times on the [Add condition] button:
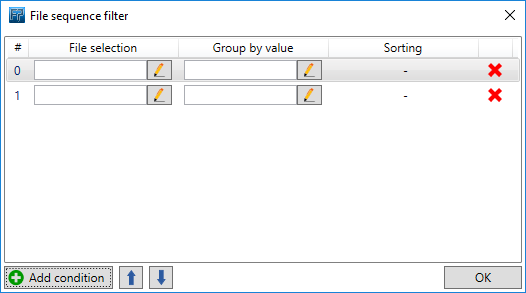
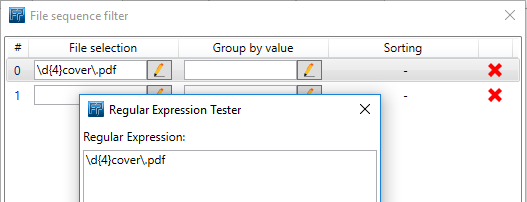
(In case you need to wait for 3 documents you can add another condition.)Use a regular expression (regex) for the first [File selection] to select the .pdf file:
\d{4}cover\.pdf
For the second [File selection] use this regex:
report\d{4}\.docx
Now we have selected both files (.pdf and .docx). The next step is to group them so that files with the number 0001 are printed together and the files with 0002 are printed together. The [Group by value] allows us to create a regular expression to select a part of the file name which will be equal in the group. As you can see the equal part to group is the number in the file name:
0001cover.pdf
report0001.docx
and
0002cover.pdf
report0002.docxFor the first condition this will be the regular expression for our [Group by value]:
\d{4}(?=cover\.pdf)
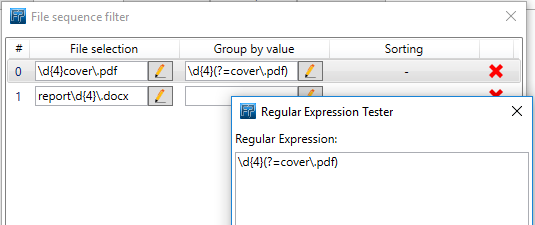
This selects the '0001' from 0001cover.pdf and '0002' from 0002cover.pdf.For our second [Group by value] the regular expression will be:
(?<=report)\d{4}(?=\.docx)
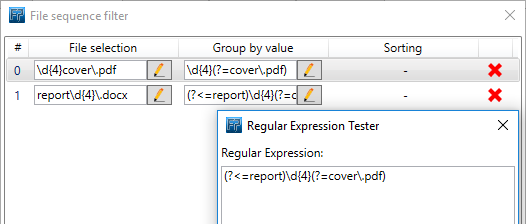
This selects the '0001' from report0001.docx and '0002' from report0002docx.The final [File Sequence] configuration will look like this:
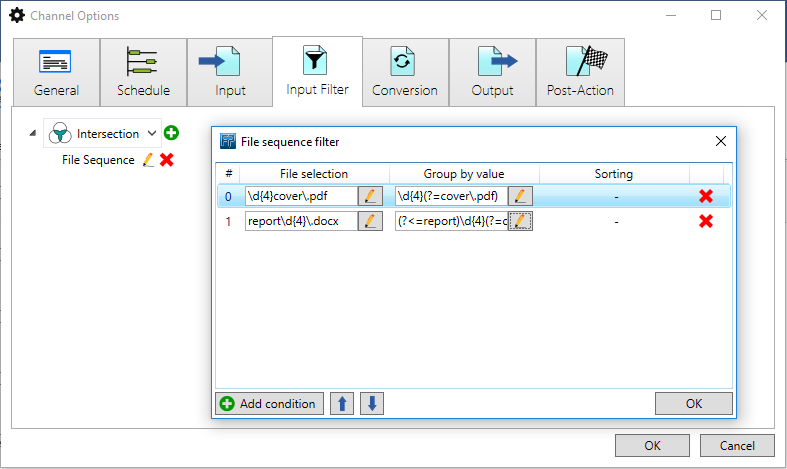
Click [OK] to close the [File Sequence] dialog.
4. Testing
You have configured your channel to monitor an hot folder as input. The input uses a [File Sequence] as an input filter to select and group documents. These documents will be printed as output.
Let's test what we've configured!
- Make sure you are connected to the service
- Go to the configured Input directory (e.g. C:\Incoming Files)
- Create a few Word files (.docx) and PDF (.pdf) files with these names:
- report0001.docx
- report0002.docx
- report0003.docx
- 0001cover.pdf
- 0002cover.pdf
- 0003cover.pdf
- Click [Start] to start the monitoring process. Each (enabled) configured channel will now monitor for files according to its defined schedule.
If all is fine, you should see activity in your File Processor channel and your PDF files and Word documents should be printed automatically in the correct order, first the PDF cover and then the Word document and grouped by their common part in the name.